Case study of a semantic library underpinning the four-corner model for document exchange
The four-corner model network topology enables parties using non-declarative data to leverage declarative content in a document exchange network, thus triggering the network effect of enabling each new user to access all existing users without knowing their trading partner's use of non-declarative data.
- Semantics,
- Semantic components,
- XML,
- XSD,
- Business documents,
- UN/CEFACT CCTS,
- OASIS UBL
Table of contents
- Abstract
- Keywords
- Introduction to business document exchange
- The four-corner model for document exchange
(business or otherwise) - OASIS Universal Business Language (UBL)
- Open-edi standards ISO/IEC 14662 and ISO/IEC 15944
- CCTS: semantic modeling for business documents
- Expecting the unexpected
- Conclusion and implications
- Interesting use of Internet’s DNS
- Biographical notes
Introduction to business document exchange
Business documents such as invoices, purchase orders, and waybills have been exchanged between the computer systems of trading partners for decades. Each of the sender and the receiver agree on a choreography of exchanging information back and forth, but each are using different applications that have independently developed different data models within which to express the document information.
For most of this time the exchange bridging the two data models has been using paper, as shown in Figure 1.
The electronic equivalent of the business document in a two-corner model network topology would require the sender’s application to serialize the sender’s data model into a stream of bytes that can be interpreted by the receiver’s application in order to populate the receiver’s data model. But there is impedance in this because the data models are not the same and/or the formats are not the same, as shown in Figure 2.
What the sender and receiver need is a common declarative basis upon which to exchange document information. But, importantly, such must be available to both with the least amount of disruption to the sender and receiver.
This paper is a case study of how an example four-corner model for document interchange addresses this need by leveraging the Organization for the Advancement of Structured Information Standards (OASIS) Universal Business Language (UBL) declarative semantic library and interchange syntax.
The four-corner model for document exchange
(business or otherwise)
One way to avoid the document impedance is to use the three-corner model topology where both parties delegate the responsibility for interchange to a common third party intermediary who assumes the responsibility of moving the information from one format to another format. Such was very popular starting around the 1990s in projects run by large prime contractors promising to solve all of the problems of both of the parties:
But such delegation of responsibility has many challenges, attractive as it may seem on the surface. There are questions of data sovereignty (where in the world is my data being stored?), data integrity (how do I know the information is being properly interpreted?), and data security (why is all my data in one place that might be vulnerable?).
One hears the call “simply use declarative markup and all your problems will be solved!” Though we know this is not that simple.
It isn’t enough simply to have a declarative interchange vocabulary with which to exchange semantics. Before going into the detail of UBL as an example declarative interchange vocabulary, consider the impact of imposing any declarative interchange vocabulary in an document exchange scenario:
Yes, interchange is achieved, but both parties have incurred the burden of syntax integration and syntax format mapping. The sending party has to generate the declarative markup containing the document content and the receiving party has to interpret the declarative markup in order to obtain the document content. It may be that either or both parties are not equipped to modify their applications to meet this need.
Consider, then, the four-corner model network topology where each trading partner has their own independent delegated network representative, called an “access point”, responsible for sending their data over the network and receiving the data from the network, as shown in Figure 5.
In this topology, the access points are either contracted out to other companies as services or built in-house. The sender’s access point is responsible only for knowing the sender’s data format, without any knowledge of the receiver’s data format. Similarly, the receiver’s access point is responsible only for knowing the receiver’s data format, without any knowledge of the sender’s data format.
Both access points know the declarative document interchange format, and in this example that is UBL. But a four-corner model network can pick any one declarative format to be the method of conveying document content.
This network topology was introduced to the e-commerce XML world by the Peppol project in Europe, as shown in Figure 6.
Note how there is no hardware being introduced between access points: this is a true peer-to-peer network with no intermediaries. The access point is a trusted network representative, and the connection between the trading partner and their access point is private, secure, and unknown to all other parties. Thus there are no questions of data sovereignty. There are no repositories vulnerable to attack. The peer-to-peer exchange is accomplished using robust and secure point-to-point connections with no intermediaries.
The lack of any central hardware makes the network resilient and effortlessly expandable, as shown in Figure 7.
This topology is very resilient to falling apart. Trading partners can choose to change their access point provider at any time, or use multiple access point providers, one for each of different document types to be supported. Consider in this example that an access point has gone out of business, in which case the trading partner can employ the services of another access point, even if it is servicing other trading partners, as shown in Figure 8.
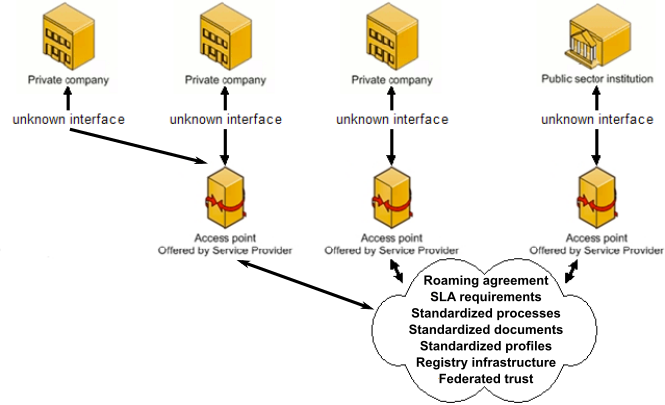
Once each access point can successfully interchange with one trading partner, it can successfully interchange with every member of the network.
What makes this topology successful is the use of a single, declarative, adopted interchange syntax between access points. In the example of the four-corner models for Peppol (worldwide), and Business Payments Coalition (BPC - US), this interchange syntax for business documents is UBL. Notably, the BPC also is implementing a four-corner-model network for remittances, using the same architecture but with the ISO 20022 syntax between access points.
The sending access point is responsible for converting the private sender format into UBL, and the receiving access point is responsible for converting UBL into the private receiver format. This is illustrated in an image from the BPC project:
In that diagram item (1) is the full UBL schema suite as published by the OASIS technical committee, (2) is a subset of the schema that isn’t required but may help with some integration tools, and (3) is an XSLT stylesheet of value validation constraints created typically (though not necessarily) from Schematron.
Figure 11 below shows Corner 3 in more detail. In that diagram, (1) is the full UBL schema suite as published by the OASIS technical committee, (2) is the BPC set of value constraints expressed in Schematron that is derived from a shared Google spreadsheet, and (3) is the XSLT stylesheet expression of the value constraints from Schematron.
The success of the four-corner model network topology is that every access point representative is using the same declarative syntax for document content, independent of the document formats used by sender and receiver in their legacy systems. In the Peppol and BPC projects for e-commerce documents, this syntax is the serialization of the OASIS UBL semantic library.
OASIS Universal Business Language (UBL)
The OASIS UBL technical committee follows the Open-edi approach separating static semantic information design from syntactic data constraint expressions. The OASIS UBL committee is over 20 years old now. OASIS UBL ISO/IEC 19845 XML is used around the world in many business document interchange networks and environments. In UBL 2.3 business concepts govern 91 separate document types as onion-skins around a common core library of over 4000 information items.
For these 91 document types UBL standardizes a published set of static business document semantics and a published set of XSD schemas. User communities are expected to adopt subsets of the semantics according to their particular business needs. Never was it the intention of the committee that any one community implement every UBL business object. Nor was it ever the intention of the committee to model dynamic business semantics as the ways that UBL is being used are as varied as the committees that are using UBL.
The sheer magnitude of the document specifications precludes human intervention, but such was not the reason to recognize the benefits in adopting how Open-edi separates the semantics of data from the syntax of data.
UBL was not designed using XML or XSD but, rather, the Core Component Technical Specification (CCTS) Version 2.01, a syntax-neutral modeling approach for hierarchical information found in business documents. The focus of committee members is the CCTS, whereas the XSD is machine generated without human intervention to produce validation artefacts that govern constraint checking of syntactic documents. The machine generation is governed by OASIS Business Document Naming and Design Rules (BDNDR).
Open-edi standards ISO/IEC 14662 and ISO/IEC 15944
The focus of UBL is on the static semantic data model of the data transfers (i.e. messages or documents), not on the dynamic semantics of the interpretation of the content (i.e. business in general or business processes). The UBL committee expressly limited their attention to how to structure the content, and not how to use the content, because there was no way the committee would conceive of all of the possible uses of UBL in the real world. Dynamic business relationships constantly change the way data is used and the expectations of the content of the data, and so the UBL committee elected solely to standardize the way the content is structured and serialized so that it could be exchanged readily and consistently. No longer would business document projects have to conceive of their own business object structures to convey commonly-understood eBusiness concepts.
This important distinction is seen in the way the international standardization community views “eBusiness”. In the early 1990s the joint ISO/IEC JTC 1/SC 32/WG 1 eBusiness standards committee working group created the ISO/IEC 14662 Open-edi Reference Model. This prescribes the separation of abstract business concepts from concrete functional implementations of those abstractions. This allows for identification, focus, and standardization in respective areas of effecting electronic business, while recognizing that the environment in which business operates works independently from a functional implementation of that environment, yet relies heavily on that functional implementation to be realized.
ISO/IEC 15944 Part 20 outlines how the Business Operational View (BOV) establishes the business environment in which trading partners are doing business, the specific business scenarios that are being addressed by an implementation, the various roles that are party to the information being exchanged in a given scenario, and the semantic bundles of information needed for the roles to perform their part in the trading partner scenario in the business environment. The specification also outlines how the Functional Services View (FSV) establishes the transport of content between trading partners supporting the choreography of the exchange of syntactic user data in fulfillment of the semantic bundles of information.
It is this reification of the information bundles as user data that bridges business semantics (the meaning of the data) from services implementing the semantics (the syntax of the data). The UBL specification document itself directly reflects the separation of the information bundles from the user data in the table of contents and the section content, as shown in Figure 13.
Also, this underscores the committee’s focus only on what information is described and how it is serialized, without any focus on how the information is used: any dynamic semantics reflecting how business is performed using the information bundles is out of scope of the UBL committee and project. The only semantics being defined are those of the information bundles being exchanged.
The UBL committee members collaborate in the abstract information bundles defined and arranged using the UN/CEFACT Core Component Technical Specification (CCTS) version 2.01 modeling principles. These principles are syntax independent. The committee then uses the OASIS Business Document Naming and Design Rules (BDNDR) to create the artefacts that govern the documents that are interchanged between access points, as shown in Figure 14.
This has contributed to the worldwide success of deploying UBL in different business environments. While the UBL committee members have created a repertoire of business objects based on general accounting and business principles, UBL user communities have cherry-picked their own set of information bundles from this. For example, the suite of UBL business objects in the information bundles used in the US Business Payments Coalition project differs slightly from the suite of objects in the bundles used in the European Peppol project.
CCTS: semantic modeling for business documents
In 1999 the United Nations Centre for Trade Facilitation and Electronic Business (UN/CEFACT) worked with the Organization for the Advancement of Structured Information Standards (OASIS) to create ebXML “Electronic Business Using Extensible Markup Language” to provide an “open, XML-based infrastructure that enables the global use of electronic business information in an interoperable, secure, and consistent manner by all trading partners”.
-
ISO 15000-1: ebXML Collaborative Partner Profile Agreement (ebCPP)
-
ISO 15000-2: ebXML Messaging Service Specification (ebMS)
-
ISO 15000-3: ebXML Registry Information Model (ebRIM)
-
ISO 15000-4: ebXML Registry Services Specification (ebRS)
-
ISO 15000-5: ebXML Core Components Specification (CCS)
The precursor to 15000-5 is the UN/CEFACT Core Component Technical Specification (CCTS) version 2.01, which was in play at the time that UBL began its development.
CCTS defines a core set of component types with content specifications and associated supplementary components. Whereas XSD data types are suitable for any kind of data, CCTS core component types are specifically designed for constructing information bundles for business documents.
Recall the base data types of XSD:
| XSD simple data type overview |
|---|
| string and string sub-types |
| boolean |
| base64Binary |
| hexBinary |
| float |
| decimal, integer, and integer sub-types |
| double |
| anyURI |
| QName |
| NOTATION |
| duration, date, and time types |
Using XSD one can compose many and varied complex types on a custom basis. Any data type can be used for the element content, any attribute can be used, and any attribute can be of any XSD type that can be selected by the XSD designer.
In contrast, using CCTS one cannot compose any custom base data types, as one is obliged to use only the Core Component Types (elements in XML), their Secondary Representation Terms (derived elements in XML), and their pre-defined properties called Supplementary Components (attributes in XML):
| Core Component Type (CCT) | CCT Supplementary Components | ||
|---|---|---|---|
| Name | Base | Secondary | Name (all are strings) |
| Amount | decimal | Currency Identifier | |
| Currency Code List Version Identifier | |||
| Binary Object | base64 binary | Graphic, Picture, Sound, Video | Format |
| MIME Code | |||
| Encoding Code | |||
| Character Set Code | |||
| URI | |||
| File Name | |||
| Code | normalized string | List Identifier | |
| List Agency Identifier | |||
| List Agency Name | |||
| List Name | |||
| List Version Identifier | |||
| Name | |||
| Language Identifier | |||
| List URI | |||
| List Scheme URI | |||
| Date Time | string | Date, Time | Format |
| Identifier | normalized string | Scheme Identifier | |
| Scheme Name | |||
| Scheme Agency Identifier | |||
| Scheme Agency Name | |||
| Scheme Version Identifier | |||
| Scheme Data URI | |||
| Scheme URI | |||
| Indicator | string | Format | |
| Measure | decimal | Unit Code | |
| Unit Code List Version Identifier | |||
| Numeric | decimal | Value, Rate, Percent | Format |
| Quantity | decimal | Unit Code | |
| Unit Code List Identifier | |||
| Unit Code List Agency Identifier | |||
| Unit Code List Agency Name | |||
| Text | string | Name | Language Identifier |
| Language Locale Identifier | |||
Outside of the XML element content and prescribed available XML attributes implementing the Core Component Types and Supplementary Components, users of CCTS are not permitted to add any other types of elements nor any other attributes of any kind to the XML.
Users of CCTS derive unqualified data types from the Core Component Types, broken down as primary and secondary representation terms. In OASIS, the following 20 unqualified data types defined in the Business Document Naming and Design Rules (BDNDR) are available for each of the abstract business objects:
| Unqualified Data Type | Core Component Type | Restriction |
|---|---|---|
| Amount | Amount | Required currency identifier |
| Binary Object | Binary Object | Required MIME Code |
| Code | Code | |
| Date Time | Date Time | xsd:dateTime |
| Date | Date Time | xsd:date |
| Time | Date Time | xsd:time |
| Graphic | Binary Object | Required MIME Code |
| Identifier | Identifier | |
| Indicator | Indicator | xsd:boolean |
| Measure | Measure | Required Unit Code |
| Name | Text | |
| Numeric | Numeric | |
| Percent | Numeric | |
| Picture | Binary Object | Required MIME Code |
| Quantity | Quantity | |
| Rate | Numeric | |
| Sound | Binary Object | Required MIME Code |
| Text | Text | |
| Value | Numeric | |
| Video | Binary Object | Required MIME Code |
One builds hierarchical business document structures from the CCTS Core Component Types by creating three kinds of Business Information Entities (BIE). As all tree-like document hierarchies go, there are leaves with content, branches with leaves, branches with branches, and a trunk with branches.
Starting with the leaves of the tree, Basic Business Information Entities (BBIE) contain the actual document data sequences of octets, lexically constrained and structured in elements with attributes according to the unqualified data types. No octets of business content in the data stream are allowed to be anywhere other than within BBIEs.
The branches of the tree are the Associated Business Information Entities (ASBIE), each one’s shape defined by a particular Library Aggregate Business Information Entity (Library ABIE). The ABIE shape contains a combination of zero or more BBIEs followed by zero or more ASBIEs. Library ABIEs are manifest as elements only as ASBIEs and not standalone on their own.
The trunks of the tree are the Document Aggregate Business Information Entities (Document ABIE) and these are the only ABIEs that are manifest directly as elements. They, too, contain a combination of zero or more BBIEs followed by zero or more ASBIEs (see Figure 15).
UBL 2.3 has 91 document types and over 4000 constituent components (see Figure 16).
The committee members focus on the business semantics by modeling the CCTS components for UBL in a shared Google spreadsheet. ABIEs in magenta, ASBIEs in green, BBIEs in blue. This is illustrated in the following sample semantic for a postal address, as shown in Figure 17.
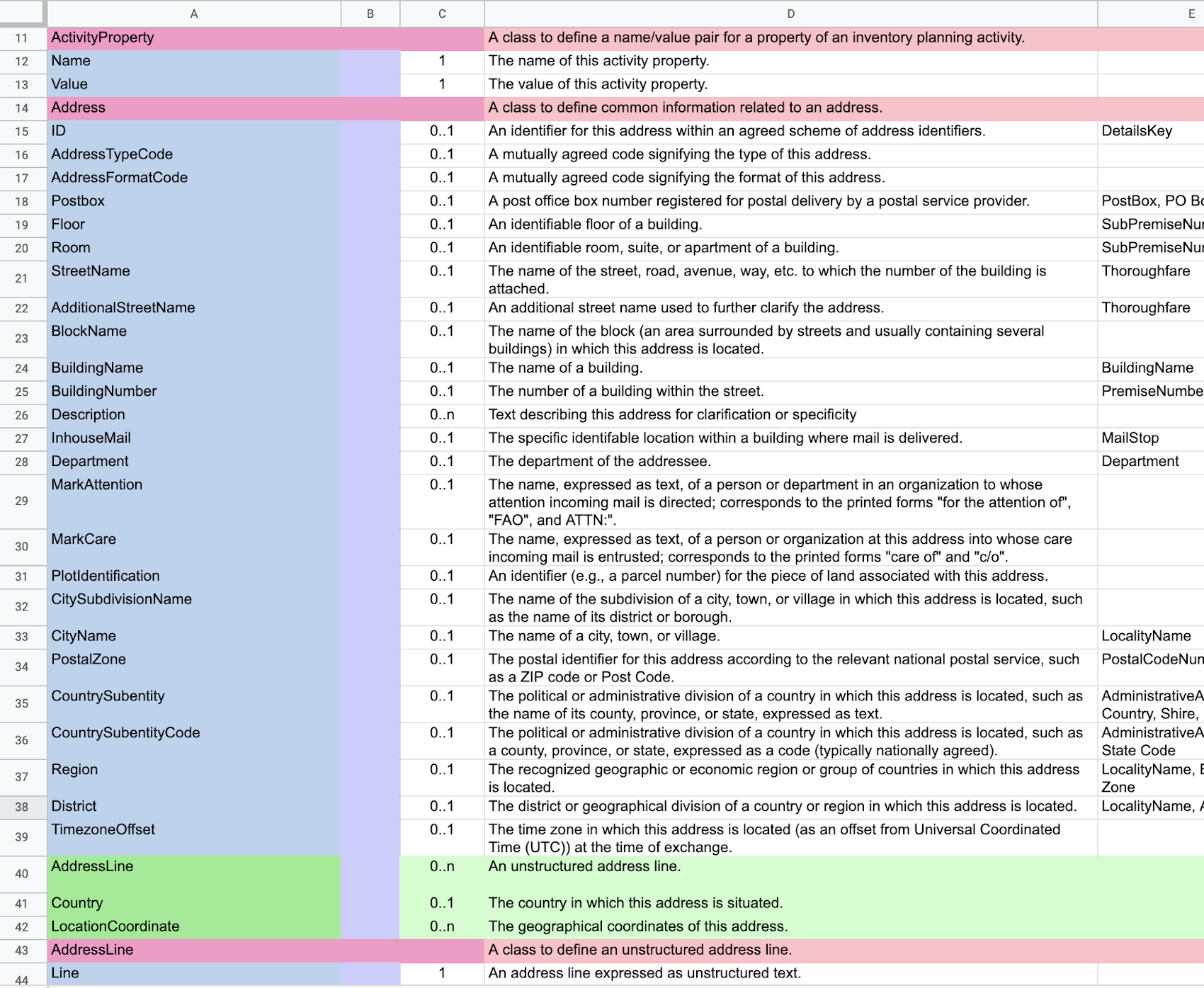
The spreadsheet has no concepts of syntax, only core component data types for the BBIE basic components. The ABIE shapes are ordered by the spreadsheet with each member component’s constrained cardinality. As a convention, all BBIEs of an ABIE are listed before the ASBIEs of the ABIE.
Expecting the unexpected
The makeup of the original UBL technical committee included a lot of XML experience. Before the XML issues were resolved and the committee became weighted almost entirely in business experts rather than XML experts, two important distinctions developed between the UBL perspective of business documents and the UN/CEFACT perspective of business documents. Both issues relate to expecting the unexpected from our users.
The rigidity of the UN/CEFACT NDR is unpalatable to the UBL committee members. In particular, all of the code lists with sets of values in a value domain are expressed as schema enumerations, and there is no accommodation whatsoever for foreign content.
Early in the development of UBL, the committee recognized that code lists are content, not structure. And the committee wanted hands off of all content, because content is the purview of the users of UBL, not the UBL committee. Accordingly, the OASIS BDNDR does not use schema enumerations for code lists. It is expected that users will use a second pass value validation that can check code lists and many other aspects of values. How that second pass is implemented is out of the scope of UBL, but the committee has created two specifications to manage code lists: OASIS genericode for enumerating coded values and their associated metadata, and OASIS Context-value Association for mapping value checks to arbitrary hierarchical contexts.
Also early in the development process, it was recognized that the UBL committee never will know ahead of time all of the requirements communities will have for their information bundles. As complete and as big as UBL has become, the committee expected that communities would have unexpected requirements. Yet CCTS does not accommodate foreign content, rigidly constraining users of pure CCTS models to know everything in advance.
The UBL committee addressed this in the OASIS BDNDR in a very flexible fashion through the availability of extension points. Prior to UBL 2.3, every document element at the root of the tree had an optional single extension point for foreign content. From UBL 2.3 and going forward, each and every branch of the document tree has an optional single extension point into which multiple extensions can be placed (see Figure 19).
User communities leveraging extensions are encouraged to use XML vocabularies that already are established and standardized by some authorities, or to re-use components from the UBL common library, but they are not prohibited from including colloquial content. The committee puts no constraints on the content of the extension point, other than encouragement to find already-standardized business objects wherever possible.
Conclusion and implications
In a four-corner model network topology, using content defined by a semantic library that is serialized in declarative syntax bridges the dissimilar systems of trading partners. Each trading partner uses their respective network representative, their access point, which is delegated the responsibility of interpreting their partner’s private, possibly non-declarative, data syntax.
Separating semantics from functional implementation promotes focus on the information and not how it is expressed in syntax. Information is more important than syntax. The approach insulates decisions in semantics from decisions in syntax. In doing so, any supporting syntax can be used and one is not limited to transliteration from other supported syntaxes.
The synthesis of document syntax schemas precludes the need for human intervention and the inevitable introduction of typographical errors when humans (at least me!) are involved.
The focus of semantic information bundles and their associated syntactic user data is insulated from the semantics of the world in which the information bundles are used and reified. Consider in this diagram how the European standards organization CEN created EN 16931 as semantic business profiles and profiled subsets of the UBL information bundles (perhaps inappropriately named “syntax binding”, though the end result does happen to be the UBL syntax associated with the UBL business objects). The CEN profiles then are used within a legal semantic business framework defined by Peppol Business Interoperability Specifications (BIS) underpinning the four-corner-model transport infrastructure:
Interesting use of Internet’s DNS
I fibbed a bit when I said that the four-corner model network topology has no hardware dependency. In fact, there is a need for the network manager to manage some registry infrastructure by supporting a DNS name server as part of the Internet’s standard DNS handling.
At any time a trading partner can abandon one access point and use the services of another access point.
At any time a trading partner can be working with multiple access points, each specializing in a different document type required by the trading partner.
This flexibility needs to be supported so that the sending access point can query which receiving access point is to be used for which document type. And it needs to do this in real time, as the trading partner can, at any time, switch off a legacy access point in favour of a new access point.
The DNS name server that the network manager implements is governed by the Service Metadata Location (SML) specification, sometimes referred to as the Business Document Metadata Service Location (BDXL) specification.
In preparation, each trading partner needs to maintain or buy the services of a Service Metadata Publisher (SMP) process that they keep up-to-date with the information about which receiving access points support documents of which allowed document types. This is how senders learn what receivers are prepared to receive.
In turn, the network’s DNS name server infrastructure must support creating, deleting, and updating facilities so that the receiver can populate the DNS entry with the IP address of the receiver’s SMP service.
This network topology then leverages Internet’s own DNS resolution to provide this flexibility to a sender by finding the receiver’s SMP directory to query.
To better understand how, first recall how DNS is used from a web browser in order to find a web site associated with a domain:
-
the end user enters www.example.com into a web browser to find a company’s web site
-
the browser asks for the company’s IP address from the Internet’s DNS resolver
-
the DNS resolver goes to the DNS root name server to find the top level domain (TLD) name server for .com
-
the DNS resolver goes to the .com TLD name server to find the example organization’s name server
-
the DNS resolver goes to the organization’s name server to find the www server IP address 192.0.2.44
-
the name server returns the web site server IP address to the DNS resolver
-
the DNS resolver returns the web site server IP address to the browser
-
the browser goes to the organization’s web site server with the address of the page desired
-
the company’s web site server returns the web page to the browser for display
Consider now the steps that Corner 2 (the sending access point) goes through to determine which Corner 3 (the receiving access point) to use to deliver the content to Corner 4 (the receiver):
-
Corner 1 asks Corner 2 to send a document to Corner 4 who has a business identifier of some recognized free-form format (e.g. a Dunn and Bradstreet number) that may have spaces or other characters unsuitable for a web address, e.g. FID#12345
-
Corner 2 translates the Corner 4 business identifier into a Corner 4 reference identifier suitable for use as a name of a sub-domain of the four-corner-model’s published and reserved Internet domain for this purpose, say 4network.net, e.g. 44d563cfaebd54.4network.net
-
the DNS resolver goes to the DNS root name server to find the name server for .net
-
the DNS resolver goes to the .net TLD name server to find 4network’s SML name server
-
the DNS resolver goes to 4network’s SML/BDXL name server to find Corner 4’s 44d563cfaebd54 SMP site IP address 192.0.2.44
-
The SML/BDXL server returns the Corner 4 SMP server IP address to the DNS resolver
-
The DNS resolver returns the Corner 4 SMP server IP address to Corner 2
-
Corner 2 goes to the Corner 4’s SMP server at 192.0.2.44 with the type of document being sent and the identifier of the choreography in which the document is being sent
-
Corner 4’s SMP server returns the 168.197.210.85 IP address for the Corner 3 that Corner 4 wants Corner 2 to use to accept the document being sent
At this point, Corner 2 can proceed with the secure peer-to-peer connection with the pertinent Corner 3.